前言
首先,在这里要感谢c0ny1师傅开发的captcha-killer插件和Nick li大佬的开源项目,还有miniboom师傅提供的思路
在平时我们进行渗透测试的时候,常常会遇到下面这种情况

在网站的验证码无法绕过的情况下,我们又需要进行网站的爆破,但爆破得填写正确的验证码进行一个认证,这种情况下可能会劝退部分小伙伴们,这个时候如何处理这种问题成为了一个值得探讨的点。
看过其他师傅的思路,在这里有一个有效的办法,就是采用深度学习的卷积神经网络对验证码进行训练识别,然后建立模型,调用burpsuite的插件captcha-killer获取识别接口进行爆破。
安装
¶cnn_captcha的安装和使用
¶项目安装及环境准备
项目为了方便已经转到我的github的仓库上,大家可以去我的仓库进行下载
1 | 项目地址:https://github.com/dota-st/cnn_captcha |
项目介绍:

项目使用python语言编写,所以需要搭建python环境,推荐下载python36版本。git clone 项目下来之后,对requirements.txt文件中的第三方库版本进行一个修改。tensorflow的版本改为1.15.3。如果你也想和我一样使用显卡来跑程序,就改成tensorflow-gpu==1.15.3。

注意:pip最好进行换源,不然下载这些库的速度可能让你怀疑人生~这里推荐换源成豆瓣源
1 | pip换源方法: |
换源之后,敲pip install -r requirements.txt命令进行下载文本里的第三方库
¶项目使用
确认安装好python的第三方库之后,就可以开始模型的训练了~
一开始,在没有图片验证码的数据集的情况下,我们可以借助gen_sample_by_captcha.py文件生成验证码的数据集
首先,我们需要去配置文件进行一个修改(当然不修改也可以)打开conf/captcha_config.json文件,修改成像我这样

一开始我们就先训练纯数字的验证码模型,设置的过于复杂,模型的训练时间也会越长,想要有良好的识别率,就不得不进行多次训练。
运行gen_sample_by_captcha.py文件,生成10000张图片文件

在sample/origin目录下可以看见生成的图片

然后sample/origin目录下新建两个文件夹,train和test(不用创建也行,代码里会自动判断有无,进行创建)
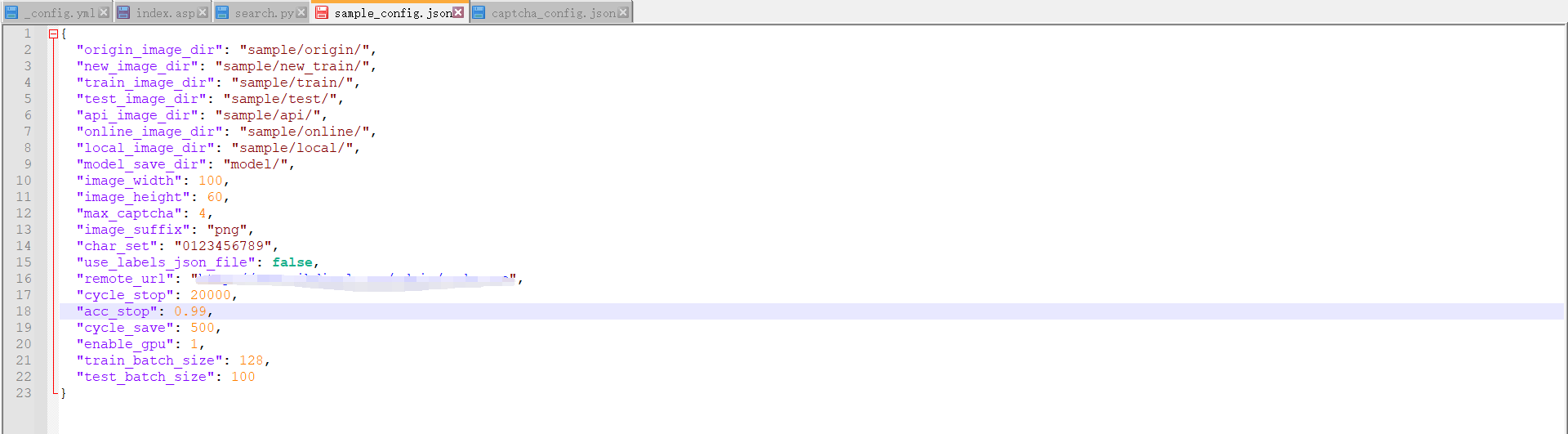
接下来需要使用verify_and_split_data.py文件,我们先看一下他的配置文件/conf/sample_config.json
1 | { |
我们进行一个简单修改,打码部分是我自定义的地址,暂时可以保持原路径不变
然后运行verify_and_split_data.py文件,程序会同时校验和分割origin和new_train两个目录中的图片,按照比例分到test和train文件夹中;

后续有了更多的样本,可以把样本放在new_train目录中再次执行verify_and_split_data。
程序会把无效的文件留在原文件夹。
此外,当你有新的样本需要一起训练,可以放在sample/new目录下,再次运行verify_and_split_data.py即可。
需要注意的是,如果新的样本中有新增的标签,你需要把新的标签增加到char_set配置中或者labels.json文件中
训练集和测试集都有了之后,接下来就是训练模型,运行train_model.py文件进行模型训练

训练模型的速度取决取决于你的电脑,可能几十分钟,可能几个小时或者几十个小时不等,可以重复多次运行文件进行训练提高准确率
这里贴张下面讲实战中使用的模型的训练图片,使用了2000张验证码图片,我的电脑跑了一分钟左右的时间吧

接下来我们运行test_batch.py文件进行一个验证

接着启动接口的api,运行webserver_recognize_api.py,此时占一个会话窗口

再次运行,默认是6000端口,这里我改成了7000端口

启动recognize_local.py文件发送请求进行一个验证

接口返回数据就ok啦~
¶captcha-killer的安装
项目地址:
1 | https://github.com/c0ny1/captcha-killer/releases |
下载好jar包之后,打开burpsuite进行安装

实战
首先使用python爬虫对网站的验证码进行一个爬取

然后按照上面的步骤进行一个模型训练
这是我本人服务器上搭建的网站
首先,我们需要抓取生成验证码文件的包,然后右键发送到captcha面板上
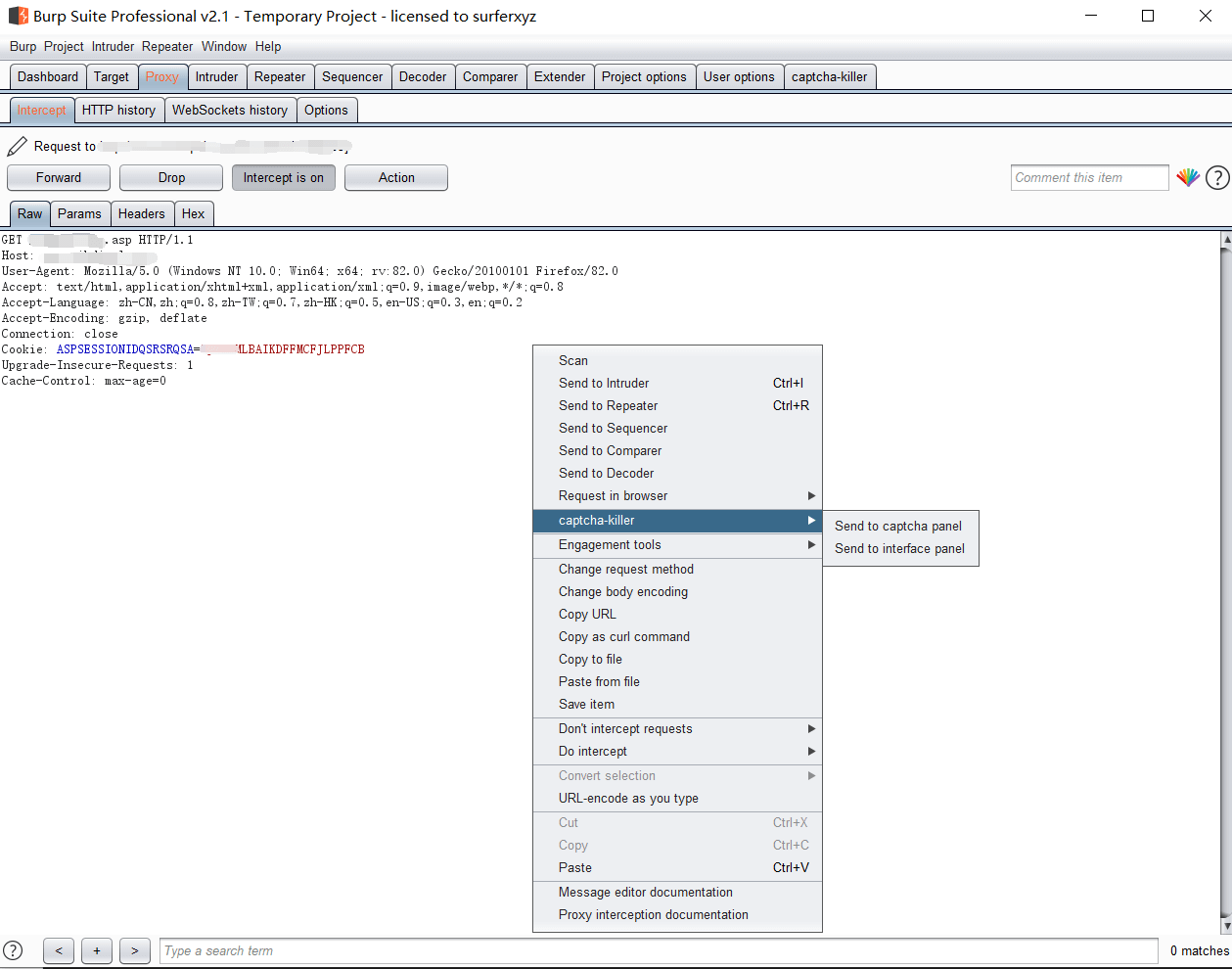
然后在killer面板上,点击一下获取,就可以出现验证码图片和信息了
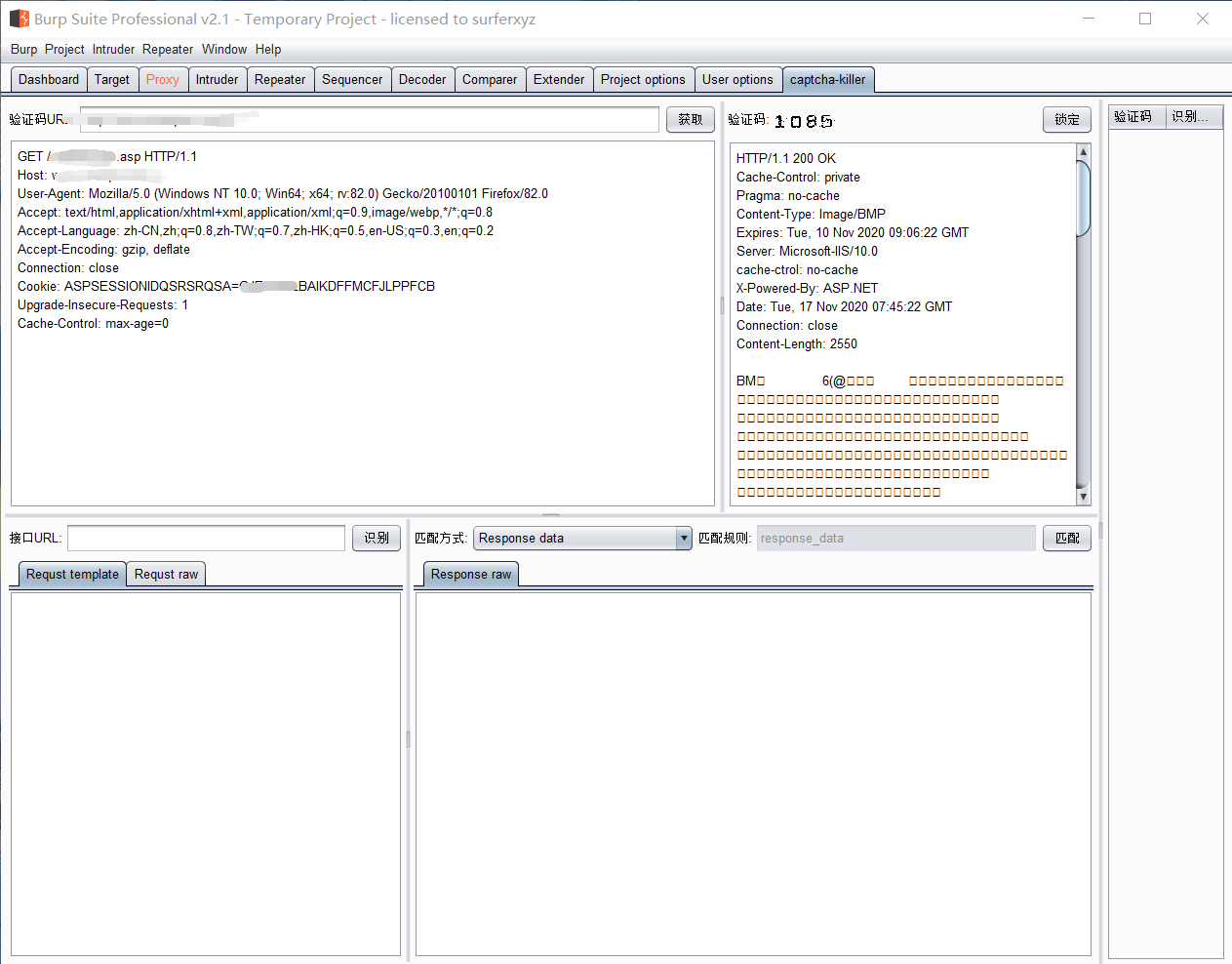
然后我们需要在webserver_recognize_api.py文件新增加一个方法
1 |
|
因为原本的方法up_image()是发送本地图片文件的形式,而我们在captcha_killer需要通过发送表单请求来进行接收
接着再发送一个requests请求,进行抓包后发送到interface面板上
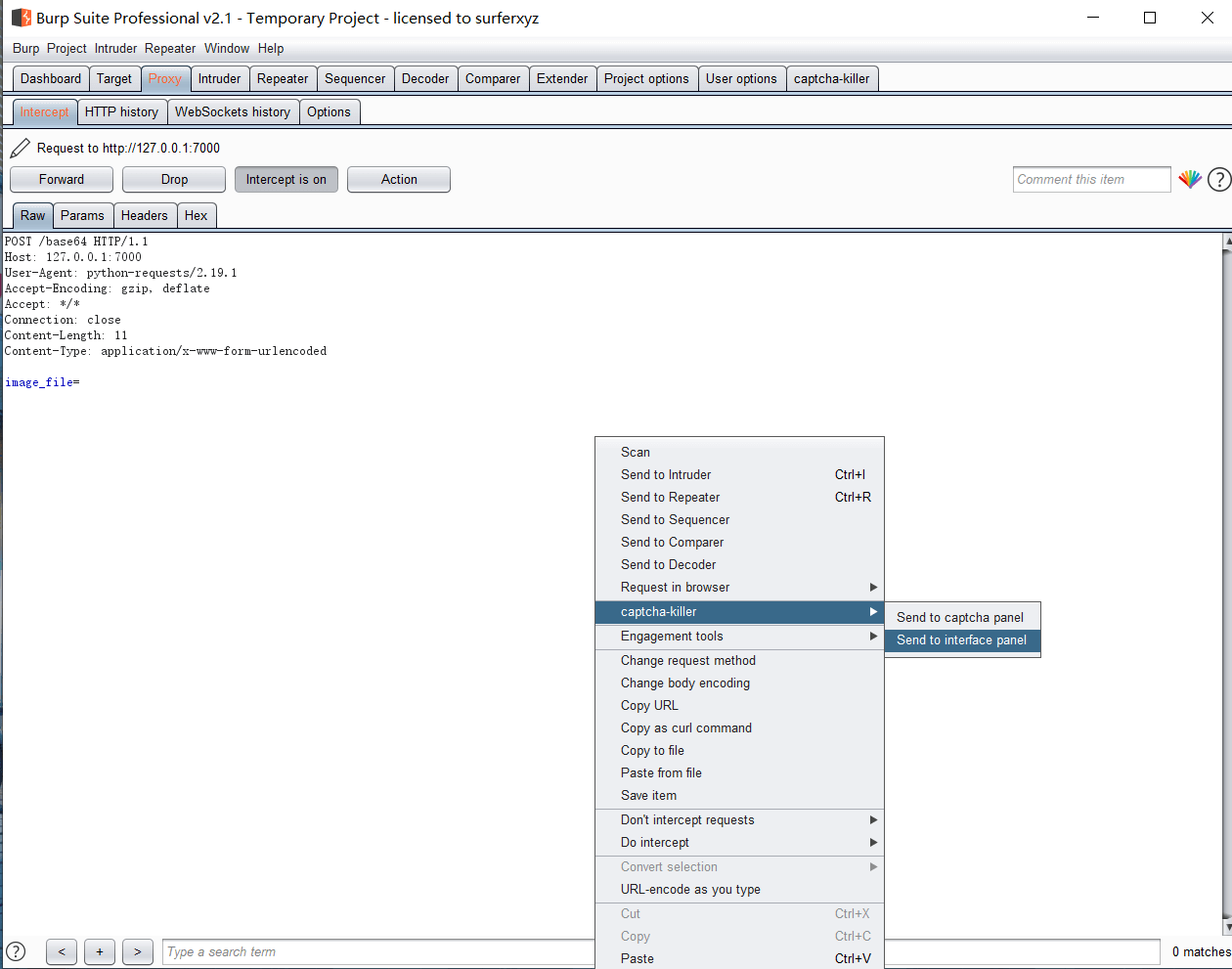
然后我们把图片内容的位置用标签来代替。
比如该例子使用的接口是post提交image参数,参数的值为图片二进制数据的base64编码后的url编码。那么Requst template(请求模版)面板应该填写如下:
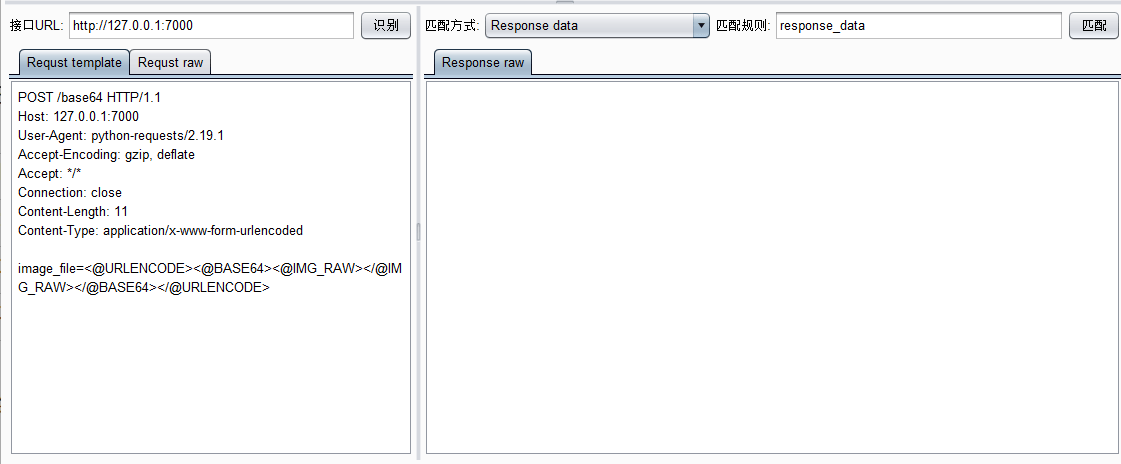
接口模板设置:
| ID | 标签 | 描述 |
|---|---|---|
| 1 | <@IMG_RAW></@IMG_RAW> | 代表验证码图片原二进制内容 |
| 2 | <@URLENCODE></@URLENCODE> | 对标签内的内容进行url编码 |
| 3 | <@BASE64></@BASE64> | 对标签内的内容进行base64编码 |
然后点击识别,即可获取到接口返回的数据包
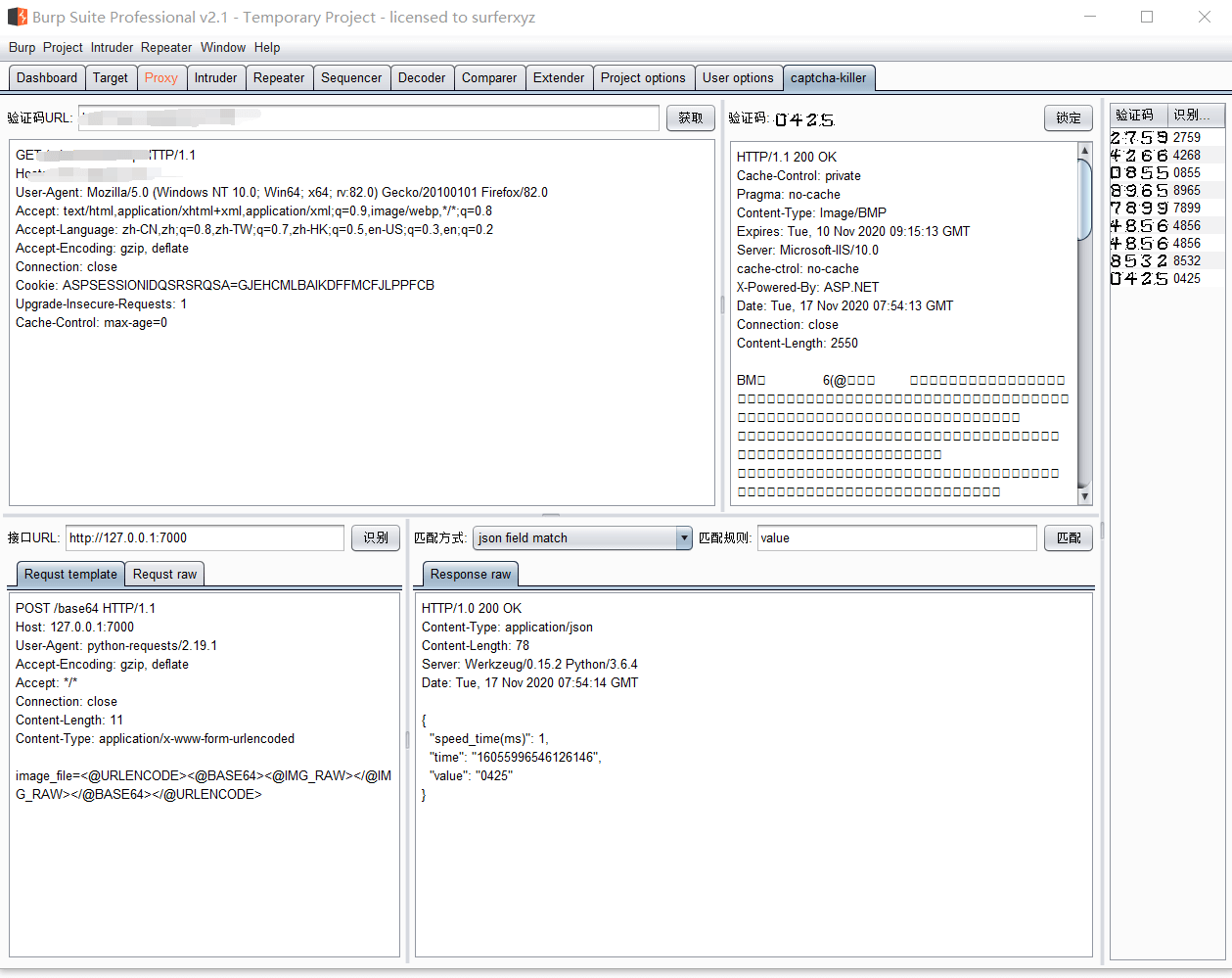
这里的匹配方式规则:
| ID | 规则类型 | 描述 |
|---|---|---|
| 1 | Repose data | 这种规则用于匹配接口返回包内容直接是识别结果 |
| 2 | Regular expression | 正则表达式,适合比较复杂的匹配。比如接口返回包{“coede”:1,“result”:“abcd”}说明abcd是识别结果,我们可以编写规则为result":“(.*?)”} |
| 3 | Define the start and end positions | 定义开始和结束位置,使用上面的例子,可以编写规则{“start”:21,“end”:25} |
| 4 | Defines the start and end strings | 定义开始和结束字符,使用上面的例子,可以编写规则为{“start”:“result”:“,“end”:”“}”} |
确认识别无误之后,点击锁定,避免一会进行爆破时出错
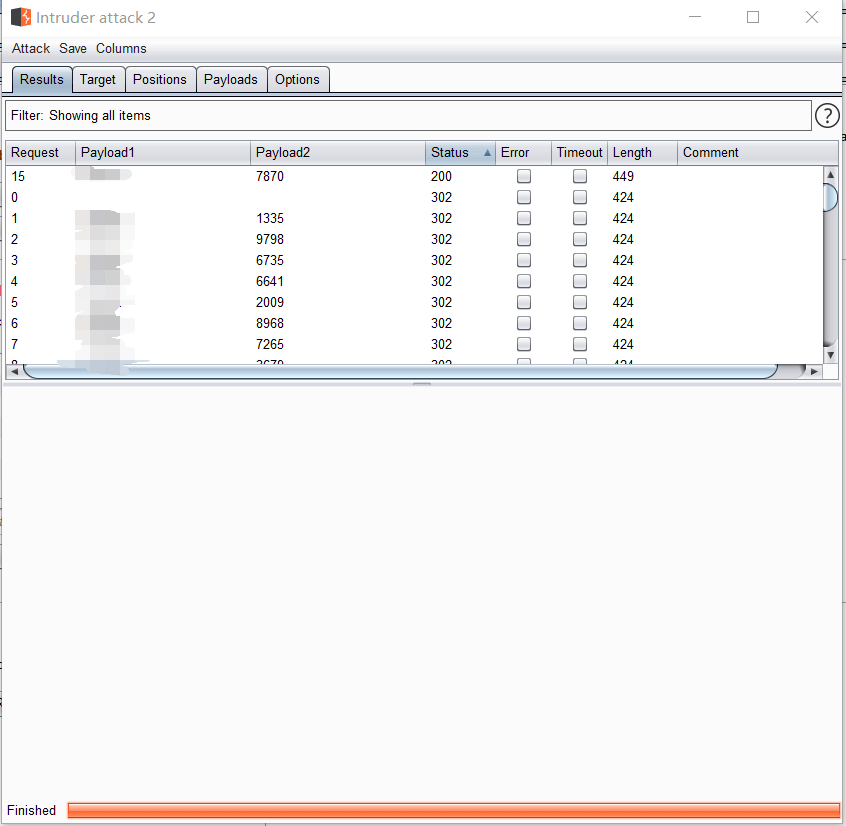
接下来我们去抓取登录界面发送的包,然后发送到intruder面板,然后设置参数
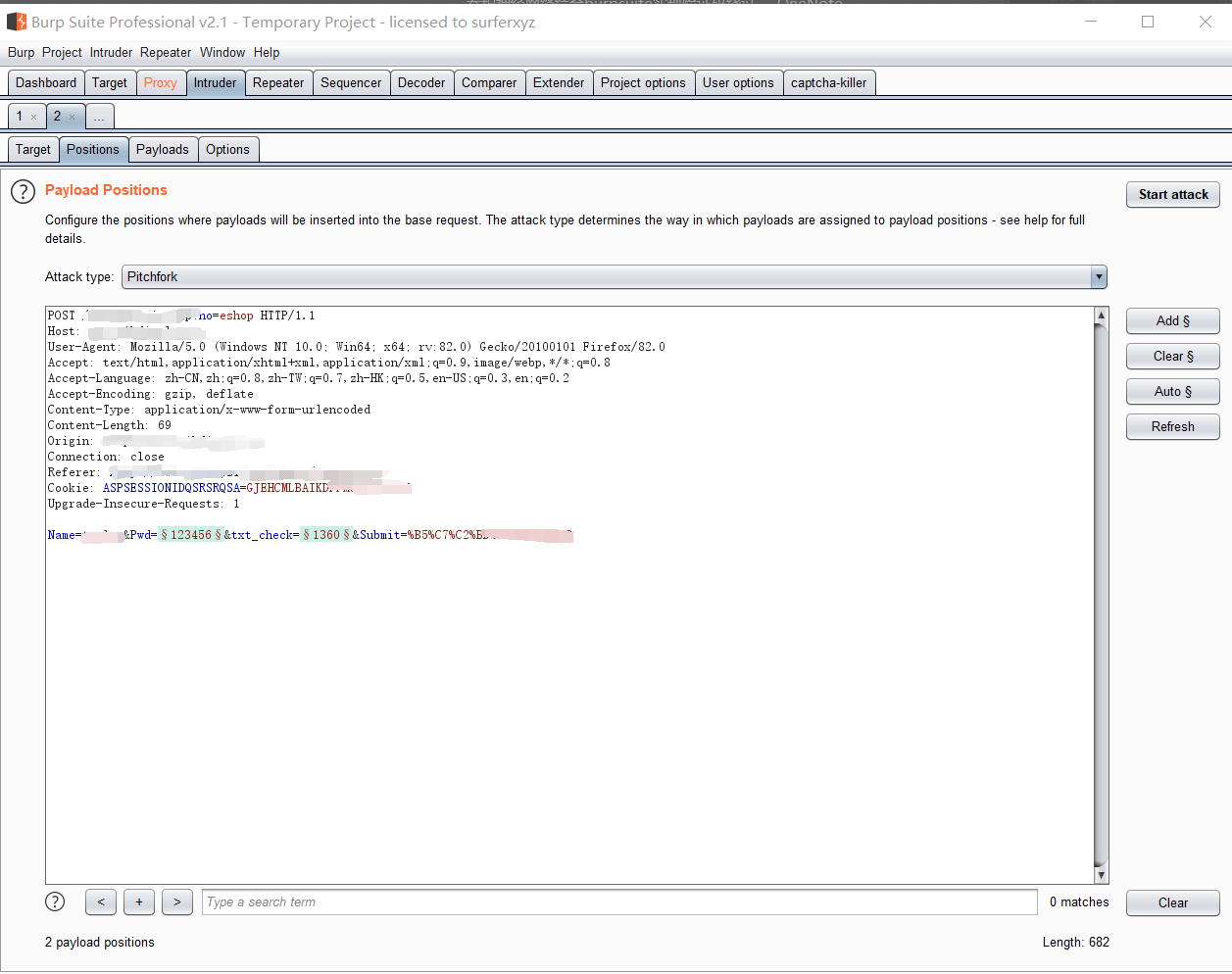
验证码的pyload选择我们的插件进行生成
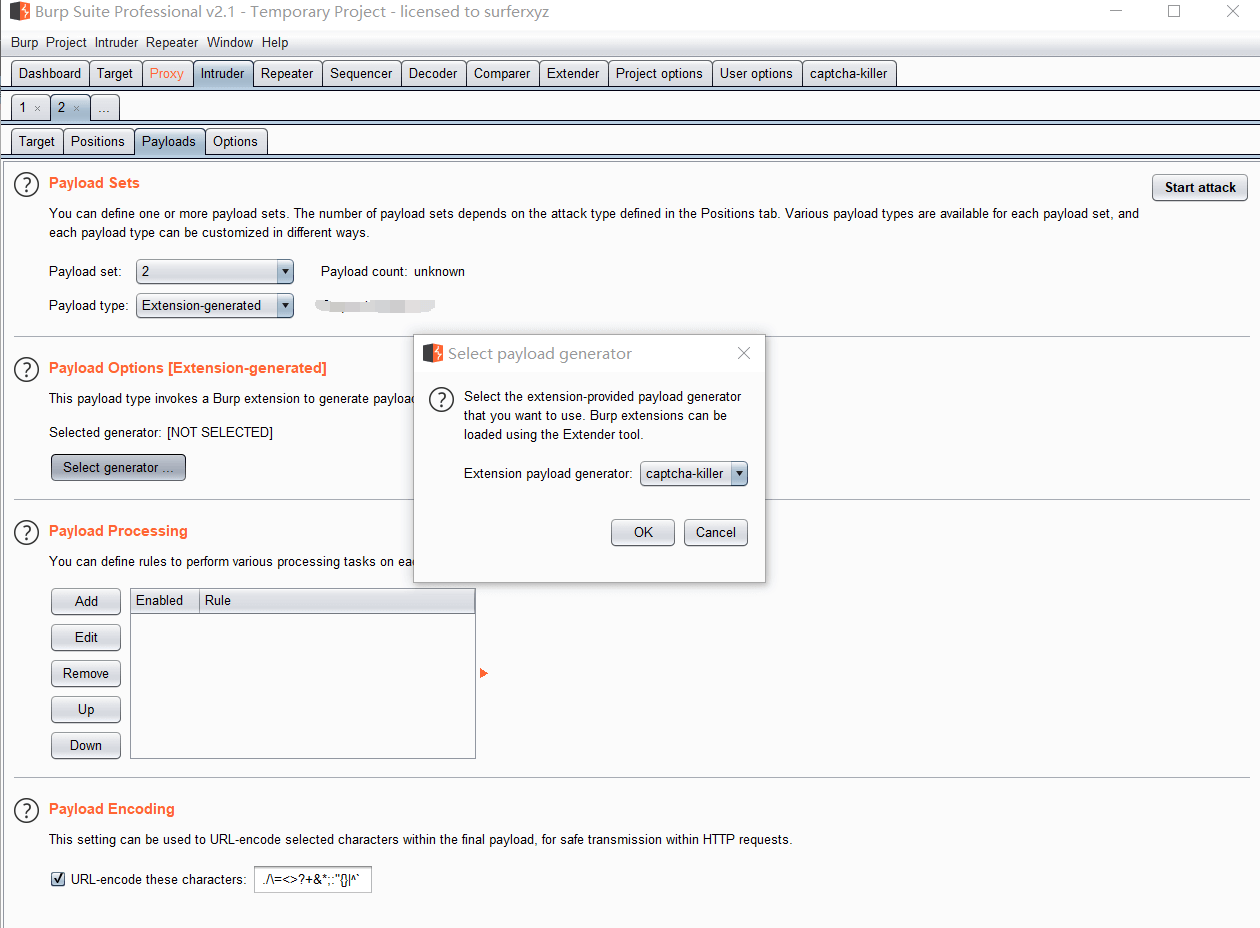
成功拿到密码
注:本博客仅供技术研究,若将其信息做其他用途,由用户承担全部法律及连带责任,本博客不承担任何法律及连带责任,请遵守中华人民共和国安全法




